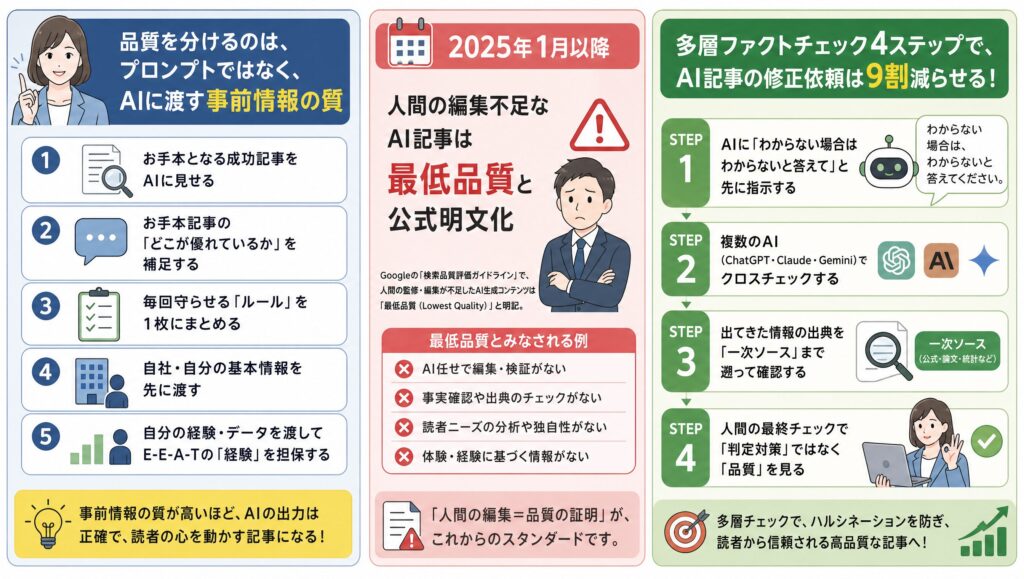
- 品質を分けるのはプロンプトではなく、AIに渡す事前情報の質
- 2025年1月以降、人間の編集不足なAI記事は最低品質と公式明文化
- 多層ファクトチェック4ステップで、AI記事の修正依頼は9割減らせる
 トール
トール今回のテーマは『AIで書いた記事の品質』について!
どうもー!トールです(@tooru_medemi)
「AIで書いた記事の検索順位が、まったく上がらない」
コアアップデートのたびにPVが落ちる、クライアントから品質を問われる、SNSでは「AI記事はゴミ」という声を見かける。正直、焦りますよね。
実は2025年1月、Googleの評価基準が静かに、しかし決定的に書き換わりました。労力・独自性・付加価値が乏しいAI生成コンテンツが最低品質ページの例として明文化されたのです。つまり「AIで書いたかどうか」ではなく「人間がどう編集したか」「どこに付加価値を加えたか」で評価が決まる時代に入りました。
この記事では、AIで150本の記事を書いて企業ドメインで8割を検索3位以内に入れてきた現場の手順から、品質を分ける「3つの分岐点」を整理します。読み終わるころには、自分の記事を診断し、明日から改善する判断軸が手に入っているはずです。

AI記事が「ゴミ」と言われる時代に、品質は何で決まるのか
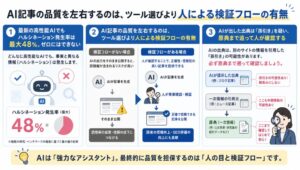
AI記事の品質は「人間の編集の有無」と「事前情報の質」で決まります。2025年1月にGoogleが最低品質の例として明文化しました。
ここ1年で、AI記事に対する市場の見方が一変しました。
Googleの検索データを見ると、「AI記事 ゴミ」というキーワードの検索数は12ヶ月で約10倍、「AI記事 うざい」は約6倍、「note AI記事 邪魔」に至っては10倍以上に急増しています(出典:ラッコキーワード実データ/2026年5月時点)。
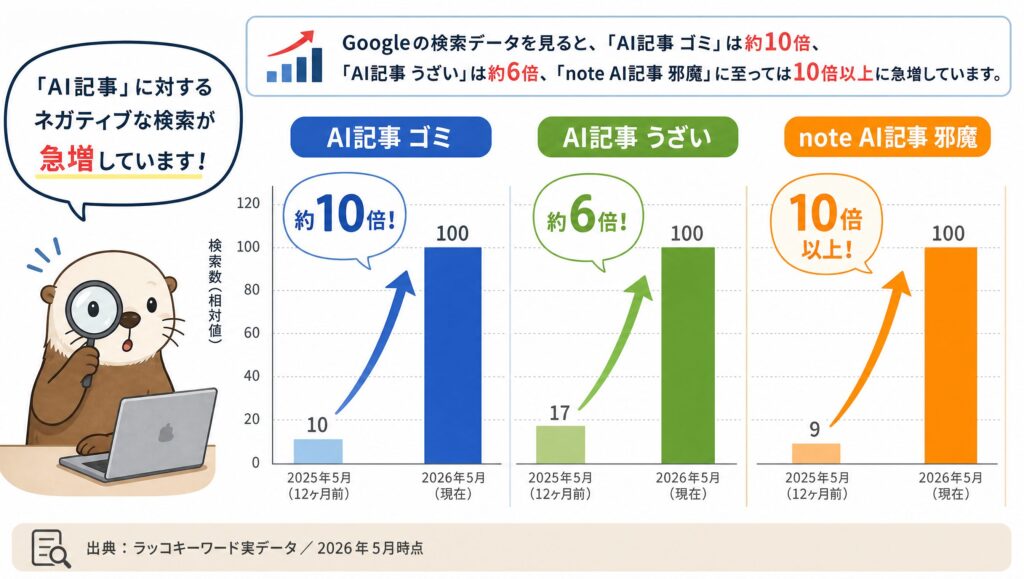
海外でも同じ流れが進んでいます。Graphite社の調査(2025年10月発表)では、2024年11月時点で英語記事の約50%がAI生成コンテンツだったと報告されています(出典:Graphite『More Articles Are Now Created by AI Than Humans』2025年)。
量だけが先行しており、読者と発注者が「AI記事の飽きと不信」を口に出し始めた、そんなフェーズに入っています。
では、品質はどの観点から測られているのか。3つの方向から整理します。
Googleの評価軸
Googleは「AI記事=ペナルティ」とは言っていません。ただし2025年1月から「労力・独自性・付加価値が乏しいAI生成コンテンツ」は最低品質と明文化されました。
「ChatGPTで書いたらバレてペナルティを受けるのでは」という心配は、Google公式の立場とは違います。
AIか人間かではなく、品質が評価軸という立場です。
実際、最新の検索品質評価ガイドライン(2025年9月11日版)でも、
生成AIで作っても高品質コンテンツは作れる、というのが公式スタンスです。
ただし、ここからが本題です。
- 2024年3月、スパムポリシーが改訂され「大量生成されたコンテンツの不正使用(Scaled Content Abuse)」が新たに追加(出典:Google検索品質評価ガイドラインSection 4.6.5)
- 2025年1月23日、検索品質評価ガイドラインが改訂され、労力・独自性・付加価値が乏しいAI生成コンテンツが最低品質ページの例として明文化(同Section 4.6.6)
- 2025年9月11日、再改訂で YMYL の4分野定義が整理(Health or Safety/Financial Security/Government, Civics & Society/その他)(同Section 2.3)
つまり「AIを使うこと」自体は問題ない、しかし「労力・独自性・付加価値のいずれも乏しいこと」は明確に評価が下がる、というのが現在の公式スタンスです。
さらに、E-E-A-Tの中で最も中心に据えられているのはTrust(信頼性)であり、AI単独では「経験(Experience)」と「信頼性」が構造的に担保しづらい点が、Googleの評価モデル上の弱点として指摘されています(Google『General Guidelines』Section 3.4)。
読者から見た品質
読者が「価値がある」と感じる記事は「検索意図の網羅」「独自性」「信頼性」の3要素で評価されます。
検索エンジンの先にいるのは、結局は人です。読者が「この記事は読んでよかった」と感じる条件は意外とシンプルで、次の3つにまとまります。
- 検索したキーワードで知りたかったことが、ひととおり書かれている
- 他のサイトでは読めない独自の視点や具体例がある
- 出典や根拠が明確で、書き手の言うことを信じられる
逆に言うと、AI生成の文章は読み続けると「機械的なリズム」「無機質な印象」を感じやすく、感情を動かす力が弱い傾向があります。これは150本ほど書いてきて毎回感じる現場感覚です。読者は「もっともらしい一般論」を読み飽きており、具体的な体験や数字が出てきた瞬間に画面に戻ってきます。
「品質 = 文章のうまさ」と捉えてしまうと方向を見誤ります。実態としては「読者の問題が解決すること」が最終評価軸です。
執筆者から見た品質
現場で150記事を書いてきた感覚では、品質を決めるのは「人間の編集の有無」と「AIに渡す事前情報の質」の2軸です。
軸の1つ目「人間の編集」は、先ほど触れたとおりGoogleの公式評価軸として明文化されました。これは外せません。
問題は2つ目の「事前情報の質」です。多くのAI記事品質論はここを語っていません。プロンプトの工夫、テンプレートの整備、編集の重要性は語られるのですが、あらかじめAIに何を渡しておくかという上流の話がほとんど抜けています。
同じプロンプトを使っても、AIに渡す事前情報の解像度で出力される文章の品質は驚くほど変わります。具体的にどんな情報をどう準備するかは、後ほど詳しく紹介します。
AI記事の品質を自己診断する5つのチェックポイント
「一次情報の有無」「一次ソース確認」「複数回ファクトチェック」「検索意図網羅」「差別化要素」の5点で、自分の記事を診断できます。
まずは、今書いている(または書いた)AI記事を、5つのチェックで見直してみてください。1つでも「できていない」があれば、そこが伸びしろです。
執筆者の一次情報(体験・データ)が含まれているか
自分にしか書けない一次情報があるかどうかで、E-E-A-Tの「経験(Experience)」が決まります。
一次情報の例は次のとおりです。
- 自社の数値(売上・成約率・継続率など)
- 顧客の声、クライアントとのやり取りで印象に残った発言
- 取材やインタビューで得た情報
- 自分自身の体験、現場での失敗談
- 業界内で共有されている暗黙知
Googleの検索品質評価ガイドラインで重視されるE-E-A-Tの「Experience(経験)」を担保する重要な要素のひとつです。また、AIが構造的に最も苦手とする領域でもあります。
逆に言えば、自分にしか書けない一次情報を1つでも記事に組み込めば、それだけで競合上位記事と差別化できます。Googleの検索品質評価ガイドラインでも、実体験に基づくコンテンツがE-E-A-Tの中心であるTrust(信頼性)を支えると明記されています。
情報源を「一次ソース」まで遡って確認したか
企業サイトに書かれた情報でも鵜呑みにせず、政府発表や公式ガイドラインの原文まで遡るのが鉄則です。
私自身、過去にこんなことがありました。
AIに記事を書かせたところ、「Google公式によると」と断定的に書かれた一節があったので念のため出典に挙げられた企業サイトを確認。確かに該当の記述は企業サイトに存在しました。
ところが、Googleの公式発表まで辿ってみると、そのような公式発表はどこにも存在しません。つまり、企業サイト側がすでに誤って書いていた情報を、AIがそのまま引用してしまっていたのです。
これは特殊な事例ではありません。AIが提示する出典URLが実在しないケースも頻発しています。一次ソースまで辿らないと「もっともらしい嘘」の連鎖を断ち切れない、これは現場の鉄則として身につけておくべきポイントです。
一次ソースの典型は、政府機関の公式発表、企業のIR資料、学術論文の原典、公式ガイドラインの原文、調査機関の生データなどです。
ハルシネーション検査を複数回(AI+人間)行ったか
最新の主要モデルでも、文書要約タスクのハルシネーション率は1〜13%。記事執筆ではさらに混入リスクが高く、1回のチェックでは見逃しが発生します。
経験上、現場では「単純にAIに書かせるとハルシネーション必発」が標準的な認識です。Vectara Hallucination Leaderboard(2026年5月11日更新版/HHEM-2.3使用)では、現行の主要モデルでも次のような数値が報告されています。
- GPT-5.4 nano (OpenAI):3.1%
- Gemini 2.5 Flash Lite (Google):3.3%
- GPT-4.1 (OpenAI):5.6%
- Gemini 2.5 Pro (Google):7.0%
- GPT-4o (OpenAI):9.6%
- Claude Haiku 4.5 (Anthropic):9.8%
- Claude Sonnet 4.5 (Anthropic):12.0%
- Gemini 3 Pro Preview (Google):13.6%
(出典:Vectara Hallucination Leaderboard 2026年5月11日更新版)
Vectara HHEMが計測するのは「50〜24,000語の文書を要約させたときの事実一貫性」です。データセットには、ニュース、テクノロジー、医療、法律、ビジネスなど7,700件以上の文書が含まれています。
ここでひとつ重要なのは、これは要約タスクの数値ということです。要約タスクは「与えられた文書の範囲内で答える」シンプルな課題なので、実際の記事執筆(自分で情報を集めて構成する)よりはるかに難易度が低いものです。要約ですらモデルによっては10%を超えるということは、記事執筆ではハルシネーション混入リスクがさらに上がる、と考えるのが現実的です。
検索意図を網羅できているか
読者がそのキーワードで本当に知りたかったことを、記事内でひととおり扱えているかを診断します。
自分の記事に「読者が知りたいことの抜け漏れ」がないか判断するには、次の3つを順に試してみてください。執筆前・執筆中・執筆後でそれぞれ役割が違うので、整理して使い分けるのがコツです。
AIに丸投げで構成案を作らせると、検索意図から逸脱しやすいというのが現場感覚です。構成だけは人間が決めて、本文生成をAIに任せる、というワークフローが現実的です。
類似記事との差別化要素が明確か
競合上位10記事の見出しを比較して、自分の記事だけにある要素を1つは明確にできているかを確認します。
差別化要素は、ざっくり3つの型に分かれます。
- 独自データ:自社の実績数値、顧客の声、調査結果
- 独自エピソード:失敗談、成功談、現場での出来事
- 独自切り口:他社が扱っていない論点、立場や視点
ここを意識せずにAIに書かせると「ネットにある情報の焼き直し」状態になりがちです。
AIで誰でも記事を量産できるようになったからこそ、一次体験・一次情報による差別化がより一層大切になっています。
順位が上がるAI記事と上がらないAI記事の決定的な違い
違いは「事前情報・工程分割・ファクトチェック・独自性・読者解像度」の5つの観点で生まれます。
これまで2年間でBtoB、BtoC領域にて150記事以上制作してきた私自身の経験から、5つの観点で、順位が上がる側と上がらない側を比べていきます。
事前情報の解像度の違い
順位が上がる記事は、AIに渡す前に一次情報・ペルソナ・検索意図・参考一次ソースを整理してから生成に入ります。プロンプト文に「BtoB企業のマーケ担当向けに書いて」と書くだけではなく、ペルソナ・課題・成果指標・自社の事例まで揃えてからAIに渡す、というイメージです。
順位が上がらない記事は、プロンプト文だけを書いて即生成。事前情報がゼロもしくは極薄の状態でAIに丸投げします。同じプロンプトでも、渡している事前情報の解像度で出力品質は決定的に変わります。
AIに渡す事前情報については、このあとで具体的にお伝えします。
工程分割と専用プロンプト運用の有無
順位が上がる記事は、リサーチ → 構成 → 下書き → 編集 → ファクトチェック → 装飾、という工程に分け、それぞれに専用プロンプトを用意しています。1工程ごとに人間が確認し、次の工程へ渡します。
順位が上がらない記事は、1つの巨大なプロンプトで「タイトルから装飾まで全部やって」と頼みます。文脈が薄まり、各工程の精度が落ちて、結果として平均的な記事になります。
私自身、工程を分割して専用プロンプトを導入してから、クライアントからの修正依頼が約9割減少しました。各工程に専用プロンプトを置く運用の効果です。
多層ファクトチェック体制の有無
順位が上がる記事は、ファクトチェックを「AI複数回チェック+人間最終チェック」の多層化で行います。AIで1回・人間で1回では足りません。
順位が上がらない記事は、AIが書いた文章をざっと目視するだけで公開してしまいます。これで誤情報が混ざると、最悪の場合は炎上に直結します。実際、自分も過去にファクトチェックを簡略化して納品し、誤情報が混入したまま公開して炎上寸前まで行ったことがあります。そこから多層チェック体制に切り替えました。
多層ファクトチェックの具体的なステップは、後ほど解説します。
一次情報・独自性の含有度
順位が上がる記事は、執筆者自身の体験・データ・取材情報がしっかり組み込まれています。AIが学習した一般論の上に、自分にしか書けない情報が乗っている状態です。
順位が上がらない記事は、ネット上の既存情報の焼き直しで、AIが学習済みの一般論で構成されています。これでは検索エンジンも読者も評価しません。
E-E-A-Tの「経験(Experience)」が直接効く領域なので、ここを薄くするのは致命的です。
読者ターゲットと検索意図の解像度
順位が上がる記事は、ペルソナを「30代マーケ担当者でAI活用経験は浅い、月の問い合わせを5件以上に増やしたい」のように具体化してAIに渡しています。
順位が上がらない記事は「広く読者向け」のような抽象的なペルソナ、または指定なしです。検索意図の解像度が低いと、文章のトーン・専門用語の難易度がバラつき、読者の離脱を招きます。
経験上、同じキーワードでも3位以内の記事と11位以下の記事を比べると、読者解像度の違いを明確に感じます。
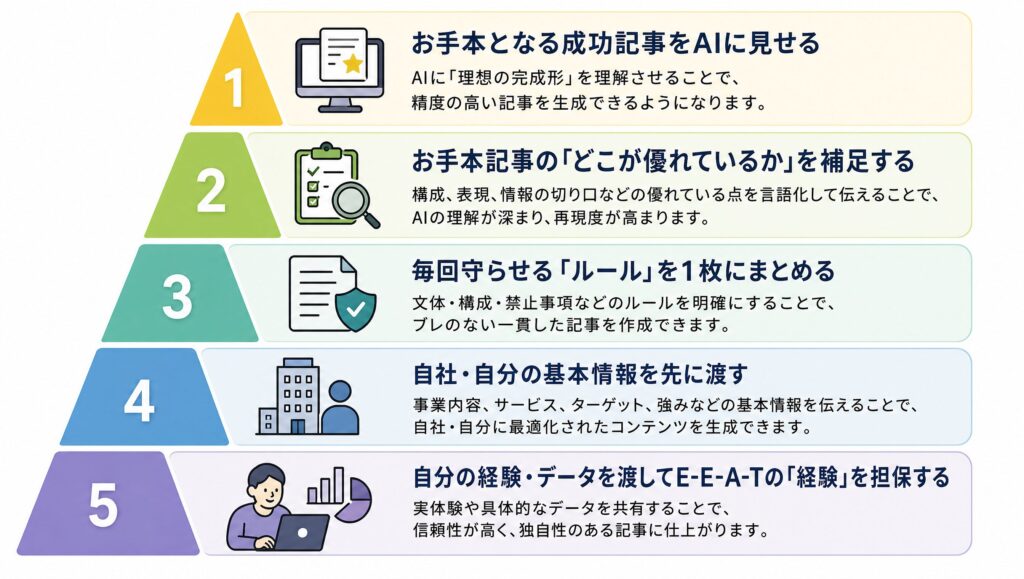
プロンプトより大事な「AIに渡す事前情報」5つの準備
プロンプトを工夫しても品質は上がりません。AIに渡す「事前情報」を5つ揃えることが、検索上位記事の決定打になります。
プロンプトテンプレを集めても品質が上がらない、という経験はないでしょうか。多くの人が一度は通る道です。
単純なプロンプトでは平均的な記事しか出てきません。テンプレートが世の中に大量に出回っているため、同じプロンプトを使えば同じような出力になるからです。差別化できないわけです。
また、プロンプトより上流の「事前情報の質」が記事品質を決定する、というのが現場感覚です。同じテンプレートでも、渡す事前情報が違えば出力は別物になります。
ここからは、AIに渡すべき事前情報を5つに分けて解説します。順番に揃えていくと、平均的な記事と差別化された記事の境目を超えられます。
お手本となる成功記事をAIに見せる
AIにあらかじめ「サンプル記事」を読み込ませることで、理想とする文章に近づける手法です。これだけで出力品質がワンランク変わります。
渡すサンプルの例は次のとおりです。
- SEOで検索1位を取った記事
- AI検索で引用された記事
- アクセスがぐんぐん伸びている記事
- コンバージョン率が高い商品ページ
- 反応がよいnote記事
「実績ある記事なんて自分にはない」という人も大丈夫です。「こういう文章を書きたい」と思える他人の記事や、評価されているブログ記事をサンプルとして使っても問題ありません。
AIに渡すときの指示もシンプルで構いません。
これから書く記事は、以下の記事のトンマナや読者との距離感を参考にしてください。
[サンプル記事のURL]これだけです。AIは渡されたサンプルから「読者との距離感」「トンマナの特徴」を自動分析し、以降の生成に反映します。
お手本記事の「どこが優れているか」を補足する
準備1のサンプル記事を渡すだけでも効果はありますが、もう一歩踏み込んで「どこが優れているか」を補足すると、出力品質はさらに上がります。
補足する内容は次の4つです。
- ターゲット読者:「BtoBマーケの現場担当者」など具体的に
- 狙ったこと:「課題の言語化と最初の解決策の提示」など
- 特に評価された点:「冒頭3行で読者の悩みを言い当てている」「見出しごとに具体例がある」など
- 真似してほしくないこと:「専門用語を説明なしで使う」「抽象論で終わる」など
実際のプロンプト例はこんな感じです。
上記のサンプル記事について補足します。
- 読者ターゲット:ライター業界の現場担当者
- 狙い:課題の言語化と最初の解決策の提示
- 特に評価された点:冒頭3行で読者の悩みを言い当てている、見出しごとに具体例がある
- 真似してほしくないこと:専門用語を説明なしで使う、抽象論で終わるこれを投げると、AIは「一般論ではなく現場のリアルな手触りで書く」「抽象的な原則だけで終わらせず必ず具体例を添える」「読者がその場で動ける一歩まで噛み砕いて説明する」といったポイントを内部で把握してくれます。その上で本文を生成するので、よりいい記事に近づきます。
余裕がない時はサンプルURLだけでも構いません。でも補足を加えると別物になるので、可能な範囲で添えてみてください。
毎回守らせる「ルール」を1枚にまとめる
ここが最重要ポイントです。
やることはシンプルで、自分用のルール用シートを1枚作るだけです。GoogleドキュメントでもNotionでも何でも構いません。記事執筆時のルールを箇条書きで書いていき、毎回AIに書かせる前に「このルールを守ってください」と投げます。
最も効きやすいのは禁止表現リストです。AIが使いがちな曖昧表現を、あらかじめ禁止しておきます。
- 「〜と言えるでしょう」(断定を回避する表現)
- 「〜することができます」(冗長表現)
- 「効果的」「効率的」(具体性のない形容詞)
- 「いかがでしたか」(まとめの常套句)
「効果的」と書きたいなら「何がどう効率的なのかまで具体的に書いてください」と指示する、という運用です。
このルールシートを一度作っておけば、毎回コピペするだけで使えます。品質の再現性が劇的に高まるので、面倒に感じても最初に作っておくのがおすすめです。
自社・自分の基本情報を先に渡す
ここからは、オリジナリティある記事を書くための準備フェーズです。
まず、自社や自分自身の基本情報をAIに先に渡します。そうすることで「自社サービスの価値」「自分の専門性」を活かした記事になります。
会社の場合に渡す情報は次のとおりです。
- 自社のサービスの機能
- 誰に向けたサービスか
- 競合他社との違い
- 顧客が得られる価値
- 顧客のどんな課題を解決するか
- 価格(可能な範囲で)
個人の場合は次のとおりです。
- 自分の専門分野
- これまでの実績
- 解決してきた顧客の悩み
- 自分ならではの切り口
1枚のシートにまとめておけば毎回使い回せます。「まとめるのが面倒」という時は、自社の商品ページや実績ページのURLをそのままAIに渡してしまっても構いません。AIがページの内容を咀嚼して、サービスの輪郭・独自性・読者の課題と価値提供・使える実績ストーリーを内部で把握してくれます。
これを渡さずに「キーワードはこれで、見出しはこんな感じで」と頼むだけだと、一般的でよくありがちな記事が出てきてしまいます。自社情報を渡すと、自社の強みをさりげなく組み込んだアピール記事に変わります。
自分の経験・データを渡してE-E-A-Tの「経験」を担保する
ここが最も差別化に効きます。
Googleが最重要視するE-E-A-Tの「経験(Experience)」を担保する最強の武器です。これは自分にしか提供できません。
渡す経験の例は、次のとおりです。
- 直近3ヶ月で顧客とのやり取りで印象に残った言葉
- 自分の失敗談(成功体験より価値が高い)
- 「初心者の頃にこれをやってダメだった」というような失敗のディテール
- 自社が保有している調査データ・アンケート結果(公開可能な範囲で)
失敗体験が貴重な理由は、読者がいちばん欲しがる情報だからです。成功体験より失敗体験のほうが、読者の価値になります。恥ずかしがらずに出しましょう。
渡し方は箇条書きでバーっと書き出してAIに投げるだけです。AIが内容を分析し、記事のなかに自然に落とし込んでくれます。
ちなみに、自分の経験を文章を書きながら入れていくのは案外むずかしいです。書いているうちに忘れてしまったり、後から「もっといい表現があった」と思い出したりします。先にAIに全部渡しておくほうが効率的、というのが現場の感覚です。
これら5つの事前準備については、こちらの動画で実演解説しています。AIに渡す汎用ルールも動画の概要欄に掲載中です。
ハルシネーションを防ぐ多層ファクトチェック体制の作り方
ファクトチェックは「AIへの事前指示→複数AIクロスチェック→一次ソース照合→人間の最終チェック」の4ステップで多層化します。
経験上、現場では「単純にAIに書かせるとハルシネーション必発」が標準的な認識です。ここからは、ファクトチェックを4ステップに分けて多層化する方法を解説します。
ステップ1|AIに「わからない場合はわからないと答えて」と先に指示する
最初の防御線は、生成段階で誤情報を減らすことです。
多くのAIは「自信がない時に黙る」のではなく「とりあえずそれっぽい答えを出す」設計になっています。だからこそ、プロンプトの段階で「わからないことはわからないと答えてください」と明示しておきます。
具体的には、こんな一文を加えるだけです。
私が質問または提供する情報に不足がある場合は、その旨を素直に答えてください。
推測で補完しないでください。
出典が確認できない情報には「出典不明」と明記してください。経験上、これだけでハルシネーションの発生率が体感で下がります。
「具体的な統計データや引用元を明記し、300文字程度で説明してください」のように具体性を加える指示も有効です。
ハルシネーションが起きやすいのは、最新情報、専門領域、統計データ参照、存在しないURL・論文の生成、といった場面です。対象期間・前提条件などを明示するとさらに精度が上がります。
ステップ2|複数のAI(ChatGPT・Claude・Gemini)でクロスチェックする
同じ内容を複数の異なるAIに投げて、結果を比較するクロスチェック手法です。ChatGPT(OpenAI)、Claude(Anthropic)、Gemini(Google)など、異なるAIを併用するのが基本です。
モデルごとに学習データと得意領域が異なるため、複数のAIで結果が一致した部分は信頼度が高いと判断できます。逆に、モデル間で言うことが食い違う情報は、要注意のサインです。
執筆者の運用例として、リサーチや最新情報の確認にはGemini、長文の論理構成にはClaude、汎用編集にはChatGPTといった形で使い分けています。各AIの仕様はアップデートで変わるため、自分の用途に合わせて選定するのが現実的です。
RAG(検索拡張生成)を組み合わせる方法もあります。これは外部の信頼できるデータベースや文書から情報を検索して回答を生成させる手法で、ハルシネーション対策の主流になりつつあります。
単一のAIに依存しない運用が、修正依頼9割減につながった大きな要因の1つです。
ステップ3|出てきた情報の出典を「一次ソース」まで遡って確認する
ここがもっとも見落とされている工程です。
AIが提示した情報や出典URLを、そのまま信じるのは危険です。先ほど触れたとおり、企業サイトに「Google公式によると」と書かれていても、その企業サイト自体が誤って書いている可能性があります。
一次ソースの典型は次のとおりです。
- 政府機関の公式発表(go.jp、lg.jp など)
- 企業のIR資料、公式プレスリリース
- 学術論文の原典
- 公式ガイドラインの原文(Google検索セントラルなど)
- 調査機関の生データ
AIが提示する出典URLが実在するかどうかも要確認です。AIは平気で存在しないURLや論文を提示することがあります。クリックして実在を確認し、該当箇所に本当にその記述があるかも目視する、というのが最低ラインです。
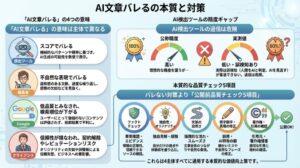
ステップ4|人間の最終チェックで「判定対策」ではなく「品質」を見る
最後の防御線が、人間による最終チェックです。ここで見るべきは「AI判定ツール対策」ではなく「コンテンツの品質」です。
AI判定ツールのGPTZeroやOriginality.aiは、ベンダー自社申告では99%や83〜100%といった高精度を公表しています。一方で独立検証(Scribbr 2024年テスト)では、Originality.aiが76%、GPTZeroが52%という結果も報告されており、ヒューマナイザーと呼ばれる回避ツールも進化しているため、判定を回避するだけならそれほど難しくありません。
ただ、Googleの本来の目的はAI検出ではなくコンテンツ品質評価です。実際、検索品質評価ガイドラインでも「生成AIツールの使用そのものは品質評価の決定要因にならない」と明記されています(Google『General Guidelines』Section 4.6.6)。
判定対策にエネルギーを使うより、E-E-A-Tの中心であるTrust(信頼性)を一次情報と一次ソース確認で固めるほうが本質的です。
人間の最終チェックで見るべき観点は次のとおりです。
- 数値・固有名詞の正確性
- 文脈の自然さ、論理の飛躍がないか
- 読者にとっての価値、独自性があるか
- AI臭い表現(「〜と言えるでしょう」「効果的」など)が残っていないか
過去にファクトチェックを通常より簡略化して納品したことがあります。結果、誤情報が混入したまま公開してしまい、危うく炎上するところでした。そこから多層チェック体制に切り替え、再発はゼロです。
ここから得た教訓は次のとおりです。
- 1回チェックしたから大丈夫、は通用しない
- チェック工数をケチると、最終的に高くつく
- 自分の専門外ジャンルこそ多層チェックが必須
AI時代のライターと発注者が取るべき行動
ライターは「時短時間をリサーチに再投資」、発注者は「AI使用の是非ではなく結果で評価」が結論です。両者の評価軸の対比が次の一歩を決めます。
ここまで読んでいただいて、AI記事の品質を分ける構造がだいたい見えてきたはずです。最後に、ライターと発注者がそれぞれ取るべき行動を、視点を分けて整理します。
| 観点 | ライターが取るべき行動 | 発注者が取るべき行動 |
|---|---|---|
| AIに対する基本姿勢 | 時短した時間をリサーチ・一次情報収集・成果分析に再投資する | AI使用の可否ではなく「結果(売上・順位・問い合わせ)」で評価する |
| キャリア/成果の見方 | 「書くだけ」のライターは消える前提で、ディレクション・編集・上流工程にキャリアを拡張する | 「品質の高いAI記事」を作れる外注先を見極め、長期契約の判断軸を持つ |
| 品質担保の重点 | E-E-A-Tの「経験」を担保する一次情報・現場感覚を磨く | 外注先に「成果数値の透明性」「ファクトチェック体制」を求める |
| 使うべき判断軸 | 自分の単価が「書く速度」ではなく「成果に基づく金額」になっているか | 「コアアップデート後にPVが落ちた」事実から、ワークフローを見直すきっかけにする |
立場は違っても、AI記事の品質を上げる出発点は同じです。
「事前情報の解像度を上げる」
「工程を分けて専用プロンプトを置く」
「多層ファクトチェックを組み込む」
この3つを地味に積み上げていけば、ゴミではなく「宝」となる記事をAIで制作できるでしょう。
逆に、ここで動かなければ、コアアップデートのたびにPVが落ちる側に残ります。読み終えた今が、いちばん動きやすいタイミングです。
明日からの記事制作にそのまま組み込める専用プロンプトを、こちらのnote「たった2時間で高品質な売れる記事が爆誕!AIプロンプト【SEO・AIO対応】」にまとめています。