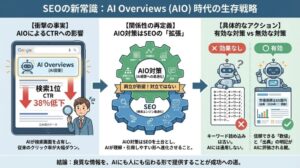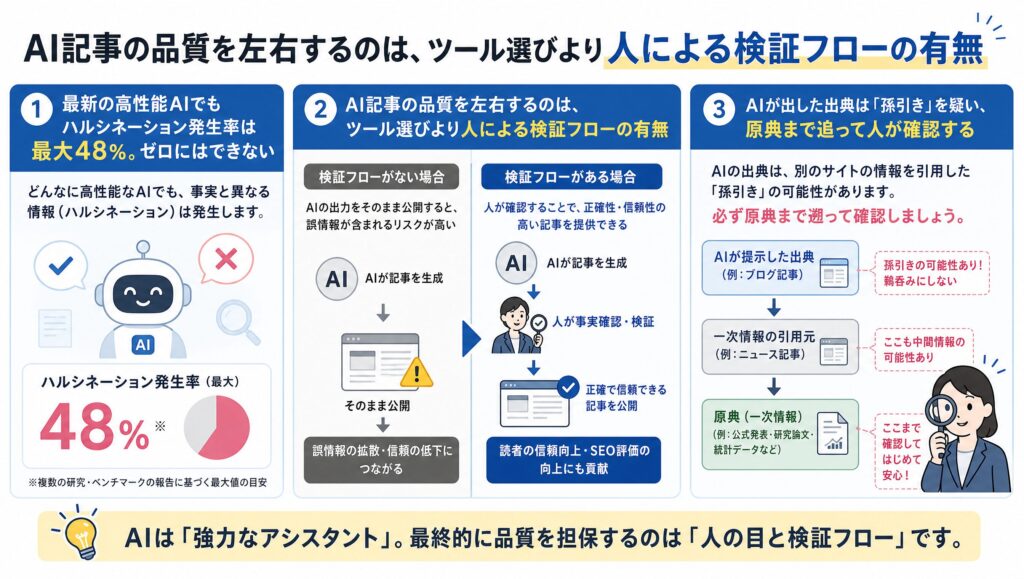
- AI記事の品質を左右するのは、ツール選びより人による検証フローの有無
- 最新の高性能AIでもハルシネーション発生率は最大48%。ゼロにはできない
- AIが出した出典は孫引きを疑い、原典まで追って人が確認する
 トール
トール今回のテーマは『AIのハルシネーションを防ぐ方法』について!
どうもー!トールです(@tooru_medemi)
AIで書いた記事を、ファクトチェックせずそのまま公開していませんか。納期に追われていると、つい「たぶん合っているはず」で出してしまいたくなりますよね。
私も一度、AIが示した「Google公式によると」という一文を疑わずに使い、危うく誤情報を世に出しかけました。あとで原典を探すと、その発表はどこにも存在しなかったのです。
もしもあのとき、誤情報を公開してしまっていたら、炎上や信頼の失墜、検索評価の低下に一直線だったかもしれません。
この記事では、ツールの紹介ではなく、あなたの制作フローのどこで何を確認すればいいのかを、5つのステップに整理しました。読み終えるころには、「これなら事故らない」と思える検証の型が手に入ります。

AIハルシネーションとは|なぜ起こるのかを理解する
ハルシネーションとは、AIが事実に反する情報をもっともらしく生成する現象で、意図的な嘘ではなく統計的な誤りです。
ハルシネーションとは、英語の hallucination(幻覚)をそのまま訳した言葉です。標準的な呼び名は hallucination ですが、一部の研究者は、より正確だとして confabulation(作話)を用いることもあります。「生成AI ハルシネーション」という言い方も同じ意味で、生成AIの出力がどれだけ事実に忠実か、という信頼性の問題に位置づけられます。
ハルシネーションのタイプは2つに分かれます。入力した内容と矛盾する「内在的」なものと、学習データにすら存在しない情報を創作してしまう「外在的」なものです。書き手が気づきにくいのは後者のほうです。
「幻覚」という比喩そのものに異論があるのは、あまり知られていません。人間の知覚障害を機械に当てはめる表現は、AIの誤りを神秘的なものに見せ、責任の所在をぼかしてしまうという指摘があります。呼び名はどうあれ、中身は次に見るとおり確率計算の産物にすぎません。この一点を押さえると、対策の向かう先がはっきりします。
AIが事実でない情報を書く原因|確率で次の単語を選ぶ仕組み
AIが事実でないことを書くのは、「正しさ」ではなく「もっともらしさ」を優先する仕組みだからです。
大規模言語モデルは、直前までの文脈から「次に来る確率が高い単語」を選んで文章をつないでいきます。事実かどうかを判定しているのではなく、言葉としての自然さを計算しているだけなので、整った文章のなかに平然と誤りが混じります。

さらにOpenAIは2025年9月の論文で、訓練と評価の設計そのものに原因があると述べました。モデルが「分かりません」と不確実性を表明するより、当てずっぽうでも答えを出すほうが評価で報われやすく、その積み重ねが推測癖を強めるという指摘です(出典:OpenAI「Why language models hallucinate」2025-09)。
曖昧な指示や、誤った前提を含んだ質問を投げると、誤りはいっそう誘発されます。
意図的な嘘ではなく統計的な誤り|AIは正誤を自己検証できない
AIは嘘をついているのではなく、自分の出力が正しいかを自分で確かめられないまま、確率的に答えを出しています。
ここを取り違えている人は少なくありません。「AIがわざと騙してくる」と身構えると、対策は「悪意を見抜く」方向にずれてしまいます。実際には、欺こうという意図はどこにもなく、たまたま確率の高い言葉を並べたら事実と食い違った、というだけです。
この理解は、地味ですが大切です。相手を「ときどき計算を間違える同僚」と捉え直せば、やるべきことは一つに定まります。人間が後ろで検算する、それだけです。擬人化して「賢いから大丈夫」「最近は嘘をつかない」と期待するほど、検証の手はゆるみ、事故に近づきます。
自分は大丈夫と思いたくなる気持ちこそ、いちばん危ういサインなのかもしれません。
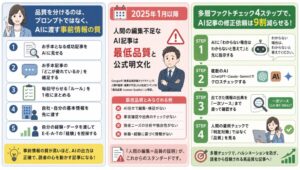
AIハルシネーションを防ぐ5ステップの検証フロー
ハルシネーション対策の核は、出典の提示・複数AIでの照合・一次情報による人の最終確認の3つです。防ぐプロンプトと5つのステップで、誤情報は大幅に減らせます。
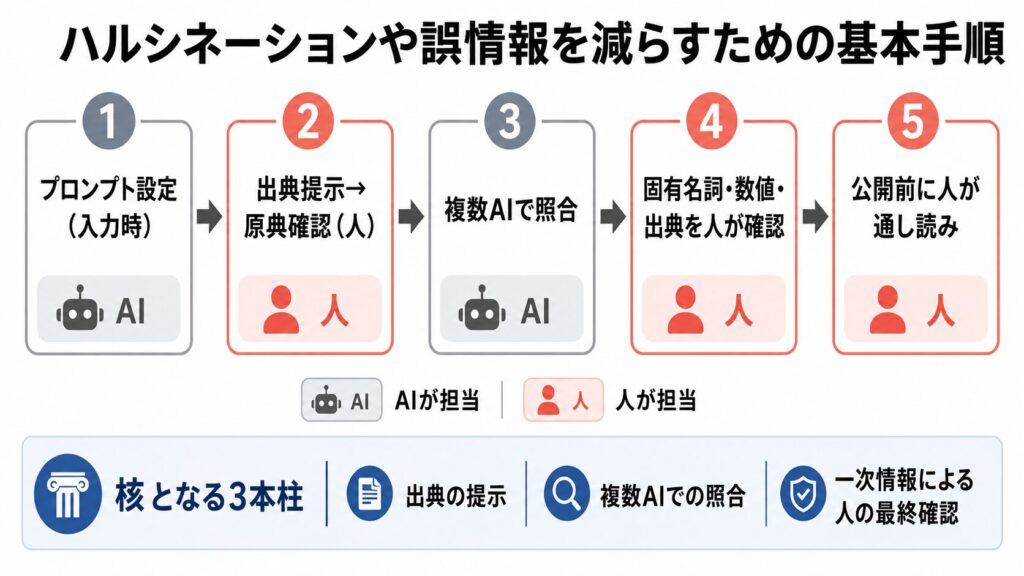
ここが一番知りたいところですよね。現場で必要なのは「自分のフローのどこで何を確認するか」を決めておくことです。私が炎上未遂のあとに固定した手順を、5ステップに落とし込みました。
ステップ1|誤りを防ぐプロンプトを入力時に設定する
最初の一手は、誤りが出にくい条件を入力時に指定することです。
「出典を必ず明記する」「分からないことは『分からない』と答える(推測で答えない)」といった点を指示に入れるだけで、根拠のない断定がはっきり減ります。役割・前提・参照してよい範囲を具体的に書き、曖昧な丸投げを避けるのもポイントです。
ただし、プロンプトの巧拙よりも効くものがあります。AIに事前に渡す情報の質です。
自分しか持っていないデータや体験、確定した数値を先に渡しておくと、AIはそこを土台に書くため、的外れな創作の余地が狭まります。凝ったプロンプトを探し続けるより、手元の一次情報を整理してから渡すほうが、品質への効き目はずっと大きい。これは、これまで150記事ほどをAIで作ってきた、筆者自身の制作経験上の体感です。
ステップ2|AIに出典を提示させ、原典まで人が確認する
AIが出した出典は、原典に当たるまで信用しないでください。
回答の根拠となるURLや原典を提示させ、それが孫引きでないかを人が確認します。ここで気を抜くと、冒頭で触れた私の失敗が再現します。AIが「Google公式によると」と書いてきたので安心して使おうとしたところ、参照元は一企業のサイトで、肝心のGoogle公式発表をたどると該当データは存在しませんでした。企業サイトに載っているからといって、一次ソースとは限らないのです。
「公式によると」「ある調査では」といった伝聞は、原典に到達して初めて事実になります。面倒に感じても、URLを開いて発表元・日付・数値を自分の目で照合する。この一手間が、孫引き由来の誤情報をいちばん確実に止めます。
ステップ3|複数のAIに同じ問いを投げて食い違いを洗い出す
同じ問いを複数のAIに投げると、怪しい箇所が浮かび上がります。
ChatGPT・Gemini・Claudeなど、性質の違うAIに同じ質問をして、答えが食い違う点を洗い出す方法です。全部が同じ誤りを犯す確率は低いので、1つだけ違うことを言い出した箇所は、まず疑ってかかる目印になります。
工程ごとにAIやチャットを切り替えるのも有効です。同じスレッドで会話を続けると、前の文脈に引きずられて誤りが固定化しやすくなります。調査・執筆・チェックで担当を変えるイメージで使い分けると、品質を保ちやすくなります。
ステップ4|固有名詞・数値・出典を疑い、人が事実を確認する
AIに下調べを任せても、事実確認の最終判断は人が握ります。
AIにファクトチェックを手伝わせて効率化するのは問題ありません。ただし「これで正しい」と確定させる役は、必ず人が担当します。AIは固有名詞や数値の正確性が低く、もっともらしい値を捏造しやすいため、具体的な記述ほど創作が紛れ込みやすいからです。
疑う対象を絞るとファクトチェックをするスピードは速くなります。固有名詞・数値・日付・出典、この4つを重点的に当たってください。公式サイトや一次ソースで裏が取れない記述は、どれだけ文章がうまくても使わない。その線引きを徹底するだけで、危ない断定はフローの手前で止まります。
ステップ5|公開前に人の目で通し読みし、公開可否を判断する
最後は、人が記事全体を通し読みして、公開してよいかを判断します。
ステップ4までで事実を一つずつ潰しても、ハルシネーションを完全には防げません。だからこそ、公開前の通し読みを最後の安全網に置きます。ここで見るのは事実の正誤だけではありません。論理の飛躍、語尾の単調さ、一般論への終始といった「AIっぽさ」も、読者の信頼を削る品質劣化として拾います。
私はこの工程を、AIで複数回チェックしたうえで人が最終確認する運用に固定しました。一度ファクトチェックを緩めて誤情報が混じり、危うく炎上しかけた反省からです。公開前チェックの担当者と確認項目を先に決めておくと、属人的な見落としも防げます。
こちらの「最大限にハルシネーション対策をしつつ、品質が高い記事が作れるプロンプト&運用ガイド」もあわせてご活用ください。

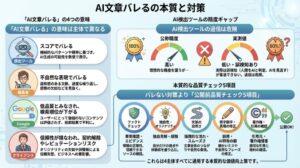
AIハルシネーションをめぐる3つの誤解と事実
最新モデルやRAGを使っても完全には防げません。推論強化型のo4-miniは48%と高く、発生をゼロにすることは原理的に困難です。
「もっといいツールを使えば解決する」という期待は、検証の手を止めてしまいます。代表的な3つの誤解を、データで解いておきましょう。
最新・高性能AIでも起きる|推論モデルはむしろ増える
「最新の高性能AIなら起きないのでは?」という問いには、データがはっきり「No」と答えます。
OpenAIが人物知識を問うPersonQAというテストで測ったところ、推論モデルのo3は33%、o4-miniは48%の割合でハルシネーションを起こし、旧モデルo1の16%を上回りました(出典:OpenAI o3 and o4-mini システムカード 2025-04)。新しく高性能なほうが、むしろ増えたわけです。
しかもOpenAI自身が、なぜ増えたのかを完全には解明できていないとしています。
各社が「新モデルは精度向上」と打ち出すので「新しい=安心」という思い込みが広がりますが、ハルシネーションに関しては成り立たないと考えたほうが安全です。
RAGを使っても嘘はゼロにならない|要約時にも誤りは残る
「RAG(検索連携)を入れれば嘘はゼロになる?」という期待にも、留保が必要です。
RAGは外部情報を検索して回答の根拠にする手法で、ハルシネーションの低減を狙えます。ところがVectaraの計測では、約7,700本超の記事を要約させる新しいベンチマークでも、裏付けのない情報や矛盾した情報が頻繁に生成されました。経済産業省の「日本のAI事業者ガイドライン」でも、RAGの効果は「抑制が期待される」という表現にとどまっています。
ここで視点を切り替えてほしいのです。品質を決めるのは、どのツールを選ぶかではなく、人間の検証フローがあるかどうかです。RAGも、前章の5ステップを回す土台の上でこそ効果が出ます。ツール探しに時間をかけるほど、肝心の検証が後回しになりがちです。
完全になくすのは困難|ベースモデルでは原理的に残る
「ハルシネーションは、いつか完全になくせる?」という疑問には、現時点では難しい、というのが大方の見方です。
OpenAIの論文や研究者の議論では、ベースモデルの段階では原理的にハルシネーションが残るとされています。モデル改良で発生率は下げられても、ゼロには届かないという前提です。
なら、どう構えるか。「ゼロにする」を目標に置くと、達成できない理想を追って消耗します。代わりに「必ず混じるものとして検証する」を前提に据えれば、やることは検証フローの整備に定まります。
完璧な道具を待つより、不完全な道具と付き合う型を持つほうが現実的です。
AIハルシネーションの実態|事故事例と発生率データ
国内でも京都市の誤情報のような実害が出ており、発生率はベンチマークによって最小3.3%から最大48%まで大きく変わります。
抽象的な不安より、実際の事故と数字を見るほうが腹落ちします。「どんな風に・どれくらい起きるのか」を確認しましょう。
国内の事故事例|京都市の誤情報と、身近な業務での失敗
ハルシネーションは海外の話ではなく、国内の身近な場面でも起きています。
2025年10月、X(旧Twitter)上の生成AIサービスが、京都新聞の記事を要約する際に誤情報を表示しました。滋賀県長浜市の施策を、京都市の施策と取り違えたのです。京都市は「このような発表や検討は行っていない」と注意喚起し、運営会社が投稿を削除しています。生成AIが作成したとみられると報じられました。SNSは拡散が速く、誤りが一気に広がる怖さがあります。
身近な業務でも、会議資料にAIが出した存在しない統計を引用してしまう、書類に架空の商品名が紛れる、といった失敗が起きています。
海外では、デロイト(豪)がAIで作成した政府向け報告書に、存在しない論文の引用が複数見つかりました。同社は契約の最終支払い分にあたる約9.7万豪ドル(約US$6.3万、約970万円)を返金しています。。
冒頭でお伝えした、私の「Google公式によると」が実在しなかった一件も、同じ構図です。要約や引用をAIに任せた瞬間、取り違えや創作は誰の手元でも起こり得ます。
どれくらいの頻度で起きるか|ベンチマークで幅がある
発生率は「単一の正しい数字」では語れず、測り方しだいで桁が変わります。具体的に並べると、こうなります。
| ベンチマーク | 測定対象 | モデル | ハルシネーション率 |
|---|---|---|---|
| PersonQA(OpenAI、2025-04) | 人物知識を問うQA | o1 | 16% |
| PersonQA(OpenAI、2025-04) | 人物知識を問うQA | o3 | 33% |
| PersonQA(OpenAI、2025-04) | 人物知識を問うQA | o4-mini | 48% |
| Vectara(2025-11) | 要約の忠実性 | Gemini-2.5-flash-lite | 3.3% |
| Vectara(2025-11) | 要約の忠実性 | 思考モデルの多く | 10%超 |
ここで注意したいのは、3.3%と48%が「別の物差し」だという点です。Vectaraの3.3%は要約の忠実性を、PersonQAの48%は人物知識を問うQAを測ったもので、そもそも測定タスクが違います。つまり3.3%から48%という幅は、同じ尺度の上での開きではなく、異なるテストの値を並べたものにすぎません。
同じデータをモデル別に並べても、「新しい=少ない」は成立しません。だから、どこかで見た「ハルシネーション率◯%」という一つの数字を鵜呑みにせず、何を・どんな用途で測った数字かまで確認する。数字の扱い方そのものが、検証力の差になります。
自分の記事にも混入する|気づくための着眼点
他人事に見えても、ありそうな顔をした誤りは、自分の記事にも紛れ込みます。
混入を見つける着眼点は、固有名詞・統計・出典・日付など「具体的な記述」を疑うことです。具体的であるほど、AIが創作で埋めている可能性があります。
京都市の事例が教えてくれるのは、「AIの要約は取り違える」という前提を持つことの大切さです。AIがまとめた内容をそのまま信じず、引用元の記事や発表を自分で開いて突き合わせる。この習慣があるかどうかが、事故るライターと事故らないライターの分かれ目になります。
AIハルシネーションを放置するとどうなるか
放置すると、誤情報の公開による炎上・信頼失墜に加え、検索評価の低下や、法的・規制上のリスクにつながります。
「忙しいから検証は後回し」が、どんな結果を招くのか。リスクを3方向から見ておきます。
リスク①|誤情報の公開で炎上・信頼失墜を招く
誤情報の公開は、ブランドの毀損と信頼の失墜に直結します。
京都市やデロイトの例のように、誤りが表に出れば、訂正やお詫び、契約面の対応まで波及します。問題は、これが「他社の特別な事故」ではないことです。私の炎上未遂も、ファクトチェックを一度ゆるめただけで起きかけました。同じ経路を、AIを使う誰もがたどり得ます。一度失った信頼を取り戻すコストは、検証にかける手間とは比べものになりません。
リスク②|検索評価が下がりSEOで不利になる
誤情報の放置は、検索評価の面でも不利に働きます。
Googleは2025年1月の品質評価ガイドライン改定で、AI生成・自動生成コンテンツの扱いを厳しくしました。さらに2026年3月のコアアップデート以降は、独自性や一次体験、E-E-A-T(経験・専門性・権威性・信頼性)をさらに重視する傾向が指摘されています。
裏取りのない記述や曖昧な出典は、評価を下げる要因になりかねません。アクセスを伸ばすために量産した記事が、検証不足のせいでかえって順位を落とす、という逆転も起こります。
リスク③|法律・ガイドライン上の責任が問われる
業務でAIを使うなら、法律やガイドライン上の責任からも目をそらせません。
医療・法務・行政といった高リスク領域では、誤情報が重大な意思決定ミスに直結します。日本でも、総務省・経済産業省のAI事業者ガイドライン(第1.2版)が、ハルシネーションをAIのリスクとして整理・拡充しました。法的拘束力のないソフトロー(Soft Law)ではありますが、「ガイドラインで名指しされたリスク」を放置していた事実は、何かあったときに不利に働きます。
AIハルシネーション対策を制作フローに組み込む第一歩
完璧を目指さず、出典確認と人による最終チェックを今の制作フローに1つ加えることが、事故を防ぐ最初の一歩です。
ここまで読んで、「全部やるのは正直しんどい」と感じたかもしれません。でも、いきなり完璧を狙う必要はありません。要点はこの3つに集約できます。
AIを「善か悪か」で語る時代は、もう過ぎました。これからの書き手に問われるのは、どの工程にAIを使い、どれだけ成果を出し、それをどう説明できるか、という測定と説明責任です。検証フローを持つことは、その説明責任を果たすための土台になります。
この記事を読み終えたあなたは、ハルシネーションの正体を理解し、自分の制作フローに組み込める5ステップの検証手順を手にした状態です。最初の一歩として、本文の5ステップをチェックリスト化して保存し、次の1記事から「AIが出した出典を、原典まで自分で開いて確認する」を1つだけ足してみてください。それだけで、事故の確率は確実に下がります。
さらに品質を磨きたいときは、こちらもどうぞ(以下)。