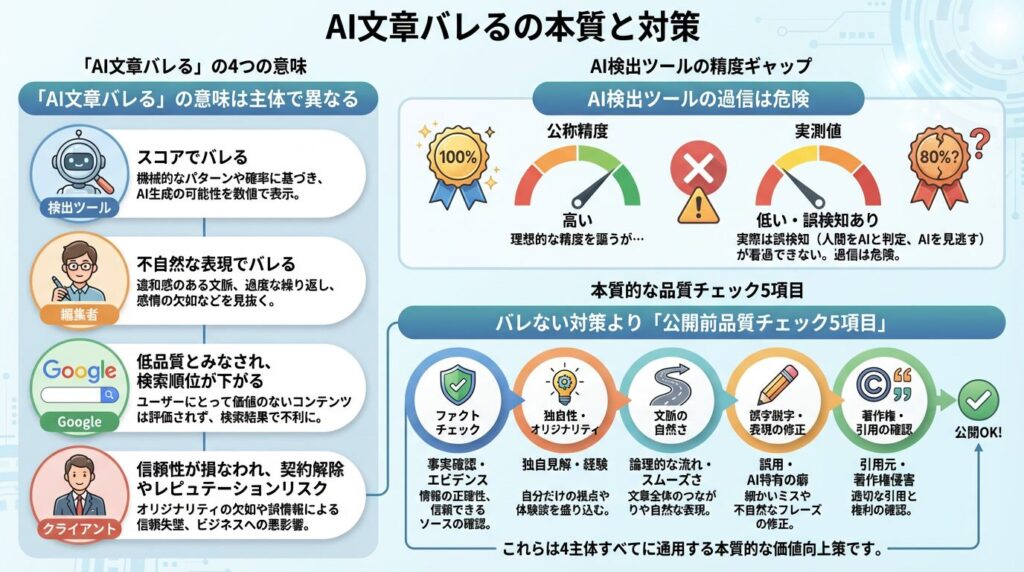
- 「AI 文章 バレる」は検出ツール・編集者・Google・クライアントの4主体で意味が違う
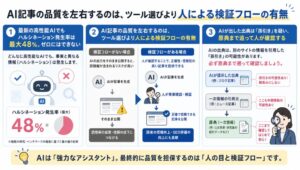
- AI検出ツールの公称精度と実測値には看過できないギャップがあり、過信は危険
- バレない対策より公開前の品質チェック5項目が4主体すべてに通用する
 トール
トール今回のテーマは『AIで書いた文章の品質チェック』について!
どうもー!トールです(@tooru_medemi)
「これAIで書きましたよね?」と納品物を疑われて、心臓が一瞬止まる感覚を味わったことはありませんか。
あるいは、対策を調べても「絶対バレる」「ほぼバレない」と記事ごとに言うことが真逆で、結局どうすればいいのか分からなくなっていませんか。
焦る気持ち、迷う気持ち、よく分かります。納品案件を失えば月の収入に直撃しますし、自サイトの順位が落ちるのを見るのは正直しんどいものです。
この記事では、なぜ世の中の解説がここまで噛み合わないのかを「4つの判定主体」に分けて整理し、Google公式の見解や検出ツールの実測データを根拠に、あなたが今日から使える判断軸をお渡しします。
読み終える頃には、「バレる/バレない」の漠然とした不安に振り回されず、公開前のひと工程として品質チェックを組み込める状態になっているはずです。

「AI 文章 バレる」は誰にバレるかで対策が変わる
AIで書いた文章のバレ方は、AI検出ツール・編集者・Google・クライアントの4主体ごとに異なり、対策も場面別に変わります。
「AI 文章 バレる」という検索の背後には、まったく違う4つの場面が隠れています。この主体を分けないまま議論するから、解説記事ごとに結論が真逆になってしまうからです。
本章ではまず、その整理マップをお渡しします。
なぜ「AI文章はバレる/バレない」の議論は噛み合わないのか
ネット上の情報を調べると、「AIで書いた文章は絶対にバレる」という記事と、「現状ほぼバレない」という記事の両方が並びます。どちらも嘘をついているわけではなく、片方は「ベテラン編集者の目で見れば」と言い、もう片方は「AI検出ツールの精度では」と言っているのです。
つまり、「誰にバレるか」の主語が抜け落ちたまま議論されているため、噛み合わなくて当然なのです。実際、主要な解説記事を読み比べてみても、検出ツールの話と編集者の話とSEO評価の話が同じ章に混ざっていることがほとんどでした。
調べれば調べるほど混乱するのは、あなたの読み方が悪いわけではなく、そもそも論点が整理されていないからです。
AIで書いた文章が「バレる」4つの主体マップ
「バレる」を成立させる主体は、大きく次の4つに分かれます。
- 主体①:AI検出ツール(GPTZero、Copyleaks、Originality.ai、NABLAS GPT検出モデルなど)
- 主体②:編集者・読者(人間の目で文体の不自然さを察知する)
- 主体③:Google(検索エンジンの評価アルゴリズムとSpamBrain)
- 主体④:クライアント・納品先(契約上のAI使用禁止条項やレギュレーション)
それぞれ、「バレる仕組み」「バレた時のリスク」「対策の方向性」がまったく違います。
同じ「バレる」という言葉でも、検出ツールに対しては技術的な話になり、編集者に対しては文体の話、Googleに対してはコンテンツ品質の話、クライアントに対しては契約遵守の話になるのです。
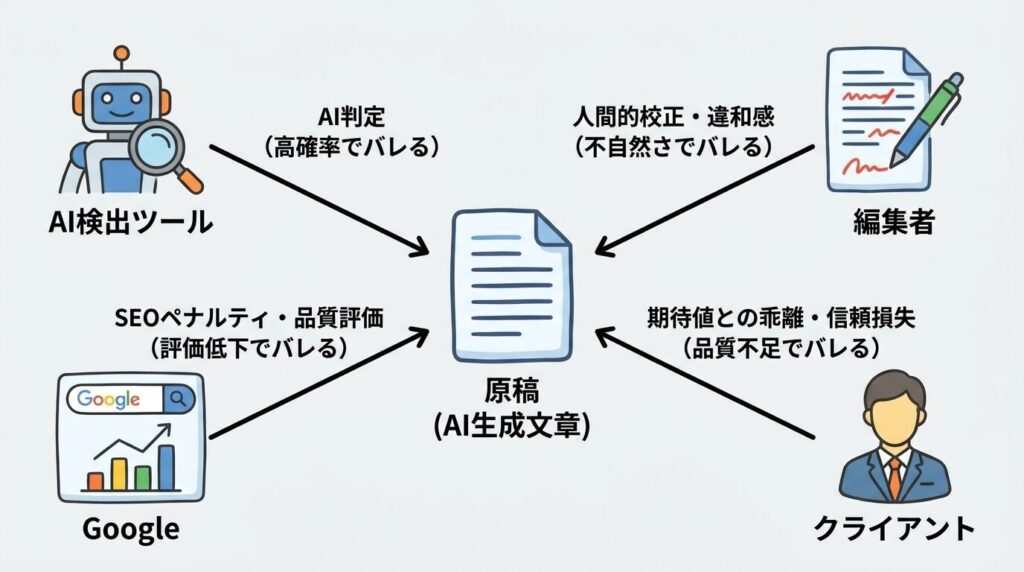
4主体ごとのバレ方とリスクの早見表
各主体ごとの違いを一覧で整理しておきます。
| 主体 | バレ方 | バレた時のリスク | 対策の方向性 |
|---|---|---|---|
| AI検出ツール | 文章のPerplexity・Burstinessをスコア化 | 偽陽性・偽陰性ともに発生、判定が確定情報にならない | ツール過信を避け、複数で照合 |
| 編集者・読者 | 文体の違和感を直感で察知 | 信頼の低下・読了率の低下 | E-E-A-T要素の注入 |
| 個別記事のAI判定はせず、サイト全体の品質傾向を評価 | 大量生成・低品質コンテンツの順位下落 | 一次情報・独自性の追加 | |
| クライアント | 納品時のチェック(検出ツール+目視) | 契約違反・継続案件の停止・報酬減 | 事前にAI使用範囲を確認・合意 |
ご覧の通り、対策は主体によってまったく方向が違います。
「人間化テクニックさえ覚えればOK」という記事をよく見ますが、これは主体②(編集者)への対策に過ぎず、主体③(Google)や主体④(クライアント)には別の対応が必要になります。
自分のケースを判別する3つの質問
自分がいま気にすべき主体はどれなのか、次の3つの質問で判別できます。
- Q1. 提出先は誰ですか?(検出ツールに通すフロー? 編集者がいる? 検索エンジン経由の流入が目的? クライアント納品?)
- Q2. 最も避けたいリスクは何ですか?(信頼? 検索順位? 契約失効?)
- Q3. 対策にかけられる時間と工程はどれくらいですか?(数分? 1記事に30分? 編集体制を組む余裕がある?)
Q1で複数の主体が当てはまる場合は、リスクの大きさで優先順位を付けます。たとえばWebライターなら主体④(クライアント)が最優先、ブロガーなら主体③(Google)が最優先、というように、自分の立場で重みが変わります。
ここからの章は、主体ごとに分けて掘り下げていきます。気になる主体の章から先に読んでもらってもかまいません。
AI検出ツールではどこまで判別できるのか?
AI検出ツールは「Perplexity(複雑性、困惑度)」と「Burstiness(バースト性、変動性)」でAI生成を判定しますが、日本語の精度は低く、誤判定事例も多数報告されています。
「とりあえず検出ツールに通せば安心なのでは?」と思いがちですが、現実はそう単純ではありません。
本章では、ツールの判定原理から、公称精度と実測のギャップ、誤判定の事例までを順に見ていきます。
AI検出ツールが判定に使う2つの指標
AI検出ツールの判定原理は、ほぼ共通して2つの指標に集約されます。
Perplexity(複雑性、困惑度):
文章の予測困難度を数値化したもの。人間が書いた文章は語彙の選び方や言い回しが不規則になりやすく、複雑性が高くなる傾向があります。逆にAIは確率的に「次に来やすい単語」を選ぶため、複雑性が低めになります。
Burstiness(バースト性、変動性):
文の長さや構造のばらつきを示す指標です。人間の文章は短文と長文が不規則に混ざりますが、AIは一定のリズムで生成しやすく、均質的な印象になります。
この理論的基盤を最初に体系化したのが、DetectGPT論文です(著者はStanford大学のEric Mitchell氏ら)。
論文では「LLMが生成したテキストは、確率関数の負の曲率領域を占める傾向がある」という観察を実証しており、現在のAI検出技術の理論的な土台となっています。
なお、Mitchell氏は論文執筆時は博士課程に在籍しており、2024年6月の博士号取得後はOpenAIに所属しています。
出典:DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature(Eric Mitchellら)
主要なAI検出ツールと公称精度
代表的なAI検出ツールと、各社が公称している精度をまとめます。
| ツール名 | 開発元 | 公称精度 | 特徴 |
|---|---|---|---|
| GPTZero | GPTZero社 | 99%を主張(混合テキストで96.5%) | 教育機関での導入実績多 |
| Copyleaks | Copyleaks社 | 99.1%・誤検出率0.2%(自社公称) | 文単位で分析、剽窃チェッカーと統合 |
| Winston AI | Winston AI | 99.98%を主張(独立テストでは84〜90%程度) | 多言語対応 |
| Originality.ai | Originality.ai | 99%超を主張 | SEO業界で利用例多 |
| NABLAS GPT検出モデル | 株式会社NABLAS(日本) | 88%(日本語特化) | GPTシリーズの日本語検出に最適化 |
数字だけ見ると「ほぼ完璧」に見えますよね。ところが、ここに大きな落とし穴があります。
公称精度と実測精度のギャップ
各社の公称値と、第三者による検証結果には看過できない差があります。Winston AIを例に取ると、公称値は99.98%ですが、独立したベンチマークテスト(axis-intelligence.com 2026年版)では84〜90%にとどまったと報告されています。
つまり、公称値は理想条件下の数字であり、実運用では1割前後の誤差が生まれる可能性があるということです。
AI検出ツール全般の性質を示すデータとして、William H. Walters氏(Manhattan College)が2023年に実施した比較研究が参考になります(De Gruyter社Open Information Science誌)。
この研究では16のAI検出ツールを比較検証しており、Copyleaks・Turnitin・Originality.aiの3ツールのみが、3つのセット(ChatGPT-3.5生成エッセイ、ChatGPT-4生成エッセイ、人間執筆エッセイ)すべてで高精度を示したと報告されています。裏を返せば、残り13ツールは条件次第で精度が大きく変動する、ということです。
出典:Fabrication and errors in the bibliographic citations generated by ChatGPT(William H. Walters 2023)
NABLAS社が日本語特化モデルを開発した際の比較実験では、次のような条件と結果が示されています。
- 比較対象:GPTZero vs NABLAS自社モデル
- サンプル数:20本の文章
- 生成モデル:GPT-3.5・GPT-4・GPT-4o(CausalLM/GPT-4-Self-Instruct-Japaneseデータセット使用)
- 文字数条件:300文字以上
- 結果:GPTZeroの日本語検出精度は71%、NABLASモデルは88%
出典:NABLAS株式会社「AI生成文章の検出モデルを開発」プレスリリース 2024年7月2日公開
20本という小規模サンプルである点には注意が必要ですが、同じツールでも対象言語によって精度が大きく変わるという事実は、「公称値」がいかに条件付きであるかを物語っています。
日本語特有の判定難易度
ほとんどのAI検出ツールは英語ベースで設計されており、日本語の文構造には最適化されていません。日本語は主語の省略が多く、文末表現も「です」「ます」「だ」「である」「体言止め」と多様で、英語のような明確なパターンが取りにくいのです。
その結果、英語で書かれた同じテーマのAI文章なら高精度で検出されるのに、日本語版では「人間が書いた」と判定されるケースが珍しくありません。
日本のWebライターやブロガーがGPTZeroで自分の記事を試して、「全部人間判定だ、安心だ」と思うのは早計だと言えるのは、まさにこの理由です。
誤判定が多発する4ケース
実際に誤判定が多発するパターンは、調査と実例から次の4つに集約されます。
第二外国語としての英語(ESL)を学ぶ書き手の文章:
Stanford大学Liang氏らの2023年の調査で、TOEFLエッセイ91本を対象としたところ、7つのAI検出器は平均61.3%を「AI生成」と誤判定し、少なくとも1つの検出器が97.8%のエッセイを誤判定したと報告されています。
引用・定型表現の多い文章:
学術論文の引用部分や、契約書のような定型句は、検出ツールがAIと判定しやすいパターンです。
発達障害特性で同じ言い回しを使いやすい書き手:
自閉スペクトラム症のMoira Olmsted氏(Central Methodist Universityオンライン課程)が、自筆の読書要約課題をTurnitinで「AI生成」と誤判定されて0点がつけられた事例が報じられています。後日再レビューで成績は修正されたものの、「次回同様の判定が出ても再レビューしない」旨の警告を受けたとのことです。なおTurnitin社はBloombergの取材に対して4%の誤判定率を認めています。
専門的すぎてパターンが少ない文章:
技術文書や法律文書のように、語彙が限定される分野は誤判定が起きやすい傾向にあります。
これらは「ツールに通っているから安全」「ツールでAI判定されたからAIだ」という単純な構図が成り立たないことを示しています。検出ツールはあくまで確率的な推定であって、判定の正解ではないのです。
ヒューマナイザーで簡単に偽装される現実
検出ツールの限界を象徴するのが、AIヒューマナイザーと呼ばれる「AI文章を人間っぽく書き換えるツール」の存在です。
Bloombergが行った検証で、興味深い事例が報告されています。GPTZeroが「98.1%の精度でAI」と誤判定した人間執筆のエッセイを、HIX BypassというヒューマナイザーAIで補正してみたところ、判定結果は5.3%まで激減したとのことです。つまり、検出ツールとヒューマナイザーが「いたちごっこ」になっているわけです。
さらに、OpenAI自身も2023年1月31日に自社のAI検出ツール「AI Text Classifier」を公開しましたが、精度不足を理由に同年7月20日に運用を停止しています。AIを開発した本家本元が「現時点での検出は信頼できる水準にない」と判断したという事実は、業界の現状をよく表しています。

検出ツールとの正しい付き合い方
ここまでの内容を踏まえると、検出ツールとの付き合い方は次の3点に整理できます。
- 補助ツールとして使い、最終判断は人間が行う:スコアを参考程度にとどめ、文章の中身そのものを編集者の目で確認する
- 1つではなく複数のツールでクロスチェック:判定結果が分かれた場合は人間が判断する
- 「検出された/されない」より「文章の品質そのもの」を見る:本記事第5章の品質チェックリストへつなげる
検出ツールを否定する必要はありませんが、信頼しすぎないことが大切です。これは過信した結果、無実の書き手が被害を受けた事例が現実に出ているためです。
人間に「AIっぽい」と気づかれる3つの典型パターン
編集者がAI文章を見抜くのは、定型的な丁寧表現、論理展開のテンプレ化、具体性の欠如の3つの典型パターンです。
ベテラン編集者は、検出ツールよりも早くAI生成を見抜きます。日々大量の文章に触れているため、「なんか違う」という違和感を数秒で察知するのです。
本章では、その「なんか違う」の正体を3つに分解します。
パターン1:定型的な丁寧表現と過剰な敬語
AIが書いた文章でまず気になるのが、過剰に丁寧で定型的な表現の連発です。
- 「〜することが重要です」「〜することが必要です」が3行に1回出てくる
- 「拝啓」「ますますご清栄のこととお慶び申し上げます」のような長い決まり文句
- 端的に伝えればいい場面で、「〜について申し上げますと」と回りくどく入る
- 「この件につきまして、ご対応のほど何卒よろしくお願い申し上げます」のような過剰敬語
これらは、AIが学習データの中で「ビジネス文章」「丁寧」というラベルに紐づいた表現を確率的に選んでいるために起きます。
読み手は「この人、いつもこんなに丁寧だっけ?」と無意識に違和感を覚えるのです。
パターン2:論理展開のテンプレ化
2つ目のパターンは、論理展開が綺麗すぎることです。
- 「結論→理由→具体例→まとめ」が章をまたいで毎回同じ順序で出てくる
- 接続詞「そのため」「しかし」「また」が機械的なリズムで挿入される
- 文末が「〜です」「〜ます」で完全に揃いすぎていて、リズムに揺らぎがない
- どの段落も同じくらいの長さに収まっている
人間が書く文章には、話題が少しずれたり、感情的な余白があったり、論理が一瞬飛躍してまた戻ったりという「揺らぎ」があります。AIにはこの揺らぎがほぼなく、結果として「上手すぎて不自然」という印象を与えます。
パターン3:具体性・体験・固有名詞の欠如
3つ目が最も本質的なパターンで、編集者が「これはAIだ」と確信する決め手になります。AIの文章には、具体的な体験・固有名詞・数値・日付が構造的に欠落しているのです。
- 「一般的には」「多くの場合」「さまざまな〜」のような曖昧な集約表現が多い
- 製品名・人名・地名・数値・日付がほぼ出てこない
- 書き手本人の体験談や失敗談、現場感がない
- 「自分はこう思う」「実際にやってみたら」のような一人称の判断が抜けている
これは、Googleが評価軸として掲げているE-E-A-T(Experience/経験、Expertise/専門性、Authoritativeness/権威性、Trustworthiness/信頼性)のうち、最初の「Experience」がAIには原理的に持てないことに直結しています。AIが書いた文章が「どこかで読んだことがある内容」に感じられるのは、当然なのです。
逆に言えば、ここを意識的に注入できれば、AIで下書きを作っても人間の編集が入った価値ある記事に仕上げられます。後ほど第5章のチェックリストで、具体的な手順をお渡しします。
編集者・読者は何秒で気づくか
文章慣れしている編集者であれば、数行読み進めただけでも違和感を覚え、1段落読み終える前に「これAIだな」と判断できることが珍しくありません。とりわけ冒頭のリード文と最初の見出し直下で違和感が出やすく、その時点で印象が決まってしまうケースが多く見られます。
そして厄介なのは、一度「AIっぽい」と判定された記事は、その後の内容がどれだけ良くても最後まで読まれにくいことです。読者の信頼が崩れた瞬間、離脱率が一気に上がります。
これはSEO的にも痛手で、滞在時間や読了率はGoogleが間接的に評価する要素とも考えられています。「バレる/バレない」以前に、読まれずに終わるリスクが先に来るわけです。
「人間らしくする」ための具体的な修正ステップ
AIで書いた下書きを人間らしく整える手順を、5つのステップに分解しておきます。
- 文末リズムに揺らぎを作る(体言止め、倒置、断定形を意識的に混ぜる)
- 固有名詞・数値・日付を意識的に追加する(「あるツール」→「GPTZero」、「最近」→「2025年9月」など)
- 自分の体験エピソードを必ず1段落挿入する
- マークダウン記号(**による太字や過剰な箇条書き)が残っていないか整理する
- 過剰な敬語と冗長表現を、普段の自分の口調に置き換える
これは「バレないため」のテクニックではなく、「読者にとって読みやすく、価値のある文章にするため」の作業です。結果として両方が同時に達成される、というのが正しい順番だと考えています。
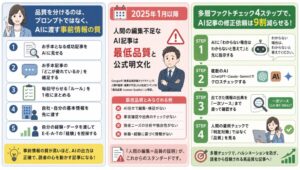
GoogleがSEO評価で見ているのは「AI使用」ではなく品質
Google公式は2023年2月以降「AIか人間かではなく品質で評価する」と明言しており、AI使用自体がペナルティ対象ではありません。
「AI記事はGoogleにバレてペナルティ」という噂が一人歩きしていますが、これはGoogle公式の見解と異なります。本章では一次ソースを引きながら、誤解を整理していきます。
Google検索セントラル公式ガイダンス(2023年2月8日)の核心
2023年2月8日、GoogleのDanny Sullivan氏とChris Nelson氏(Google検索品質チームを代表して)は、検索セントラルブログで「AI 生成コンテンツに関する Google 検索のガイダンス」を公開しました。この公式文書の要点は、次の3点に集約されます。
- コンテンツの評価軸は、作成方法(AIか人間か)ではなく品質そのものに置く
- E-E-A-T(経験・専門性・権威性・信頼性)の基準を満たすオリジナルで高品質なコンテンツを評価する
- 検索ランキング操作を主目的として自動化やAIを使ったコンテンツ生成は、スパムポリシー違反とみなす
出典:Google検索セントラル「AI 生成コンテンツに関する Google 検索のガイダンス」2023年2月8日
つまりGoogleは、「AIで書いたかどうか」を評価対象にしていません。問題視しているのは「ランキング操作目的の大量生成」であり、これはAI登場以前から一貫しているスパム対策の姿勢です。
「AI記事はペナルティ」という噂が広まったのは、SEO情報の伝言ゲームのなかで、Googleの言う「低品質な大量生成コンテンツ」が「AI記事」と短絡的に翻訳されてしまったことが大きな原因と見られます。
Googleが評価する基準=E-E-A-T
ではGoogleは何を見ているのかというと、E-E-A-Tという品質評価軸です。
- Experience(経験):そのトピックについて筆者が実体験を持っているか
- Expertise(専門性):業界知識や専門的視点があるか
- Authoritativeness(権威性):著者やサイトが分野で認知されているか
- Trustworthiness(信頼性):出典の明示や正確性が担保されているか
このうち「Experience」は、2022年12月に「E-A-T」から「E-E-A-T」へ更新された際に追加された要素です。実体験を持つ著者かどうかが、より重視される方向にシフトしているということです。
AIで書いた記事でも、E-E-A-Tの4要素を満たせば評価される、というのがGoogleの基本姿勢です。逆に言えば、AI使用の有無ではなく、これらが満たされているかどうかが評価の分岐点になります。
2024年3月コアアップデートで実際に起きたこと
「公式は中立と言っても、実際は順位が下がった」という声を聞くのも事実です。これは2024年3月のコアアップデートと、それに伴うスパムポリシーの強化が背景にあります。
このアップデートは2024年3月5日に開始され、4月19日に完了しました。Google側完了後、「当初目標の40%を上回る45%の低品質・非オリジナルコンテンツ削減を達成した」と発表しています。
同時に、3つの新たなスパムポリシー(expired domain abuse / scaled content abuse / site reputation abuse)が追加されました。とくに、scaled content abuse(大量生成コンテンツ乱用)は、AIを使った大量量産記事も明示的に対象になっています。
具体的な記事単位のデータは公開されていないものの、AIで雑に量産された記事サイトの多くが大きな順位下落を経験したことは、SEO業界の複数のデータ追跡事業者(Search Engine Journal、Amsive他)が観測しています。
現場の感覚としては、AIで下書きを作るところまでは効率化し、人手による品質チェックを最後に必ず入れる、というワークフローが現実的な落としどころだと思います。
2025年1月検索品質評価ガイドライン改定の真意
2025年1月、Googleの検索品質評価ガイドライン(General Guidelines)が改定され、第4.6.6節が新設されました。節のタイトルは「労力・独自性・付加価値が極めて少ないメインコンテンツ(MC Created with Little to No Effort, Little to No Originality, and Little to No Added Value for Website Visitors)」。
原文では、ページのメインコンテンツのほぼ全部が次の5つのいずれかに該当し、かつ労力・独自性・付加価値がほとんど加えられていない場合、最低評価(Lowest)とすると規定されています。
- 複製(copied)
- 言い換え(paraphrased)
- 埋め込み(embedded)
- AI生成(auto or AI generated)
- 再投稿(reposted)
ここで重要なのは、原文でAI生成が「複製」「言い換え」「埋め込み」「再投稿」と同列に並んでいることです。判定基準は「AI生成だから最低評価」ではなく「労力・独自性・付加価値の不足」であり、ツールが何かではなく、結果の中身が問われる構造になっています。
つまり、実体験や専門知識を加えた価値あるAI支援記事と、ボタン1つで量産された空っぽのページは、Googleの中ではっきり区別されるということです。この情報は2025年4月のSearch Central Live MadridでGoogleのJohn Mueller氏が言及し、業界に広まった経緯があります。
「Googleの公式姿勢=品質で評価」と「ガイドライン=価値の薄い大量生成は最低評価」は、実は同じことを別の角度から言っているのです。
AI使用は読者に開示すべきか
AI使用を読者に開示すべきかどうかは、多くのライターやブロガーが迷うポイントだと思います。
これもGoogle公式に答えがあります。Googleは「コンテンツ作成の一部に AI を使用していることを読み手に明確に伝えることを推奨事項としていますが、著者の署名欄にAIと記載することは、その方法としてふさわしくありません」と明言しています。
つまり、開示はする方向だが、著者欄に「AI」と書くのは違う、というニュアンスです。実務的には、
- AIを下書き作成や調査の補助に使ったことを、本文中や記事末で軽く触れる
- 事実確認は人間が行ったこと、独自の見解を加えていることを示す
- 著者欄には実在の編集責任者の名前を載せる
このあたりが現実的な落としどころです。「全部隠す」も「著者をAIにする」も極端な選択であり、どちらもおすすめできません。
公開前にできるAI文章の品質チェック5項目
定型表現の削除、固有情報の追加、論理の検証、出典の明示、独自視点の挿入。この5項目で品質を担保できます。
ここまで4主体ごとのバレ方を見てきましたが、対策をすべて個別に覚えるのは大変ですよね。実は、品質を上げる5項目さえ押さえれば、4主体のすべてに同時に効きます。
本章ではその実務手順をお渡しします。
なぜ「バレない対策」ではなく「品質チェック」なのか
ここまで読んでくださった方には、すでに薄々伝わっていると思います。「バレないテクニック」を磨くより、「文章の品質を上げる」方が、結果的にすべての主体に対する答えになるのです。
考えてみてください。
- 検出ツール対策のために文末リズムを揺らす → 結果的に読みやすくなる
- 編集者対策のために具体例を入れる → 結果的に読者にとって価値が増す
- Google対策のためにE-E-A-Tを満たす → 結果的に上位表示されやすくなる
- クライアント対策のために事実確認を徹底する → 結果的にトラブルが減る
すべての主体への対策が、「品質を上げる」という1点に集約されるのです。
「バレない技術」を磨くのは対症療法ですが、「品質を上げる」のは根本治療になります。長期的に見れば、後者の方がはるかに楽で、収益にもつながります。
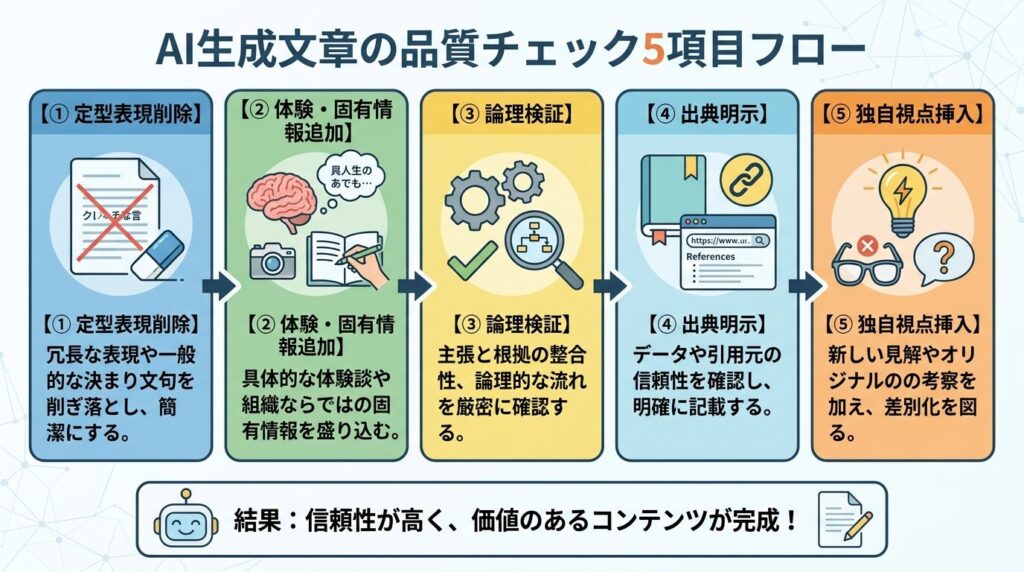
チェック1:定型表現と過剰な丁寧表現を削る
AIで生成した文章を開いたら、まずやるべきは定型表現の検索置換です。
- 「〜することが重要です」「〜が必要です」「〜と言えます」を別の言い回しに置き換える
- 「拝啓」「お世話になっております」「お慶び申し上げます」のような長い決まり文句を整理する
- 文末が3回連続で「〜です。」になっていたら、1つは体言止めや「〜になります」に変える
- 「ぜひ」「まず」「最後に」が連発している箇所は、不要な方を削る
エディタの検索置換機能を使えば1〜2分で終わる作業ですが、これだけで文章のリズムがぐっと自然になります。
チェック2:体験・固有名詞・数値を加える
AIが書いた文章には「体験」と「固有情報」が抜け落ちているので、ここを意識的に注入します。
- 自分の体験エピソードを最低1段落、本文中に挿入する(失敗談は特に効果的)
- ツール名・人名・地名・製品名を3つ以上、本文に追加する(「あるツール」→「GPTZero」のように具体化)
- 数値や日付を意識的に明記する(「最近」→「2025年9月」、「多くの企業」→「41.2%の企業」のように)
- 一人称の判断を加える(「私はこう考えています」「実務ではこう対応してきました」など)
これが、E-E-A-Tの「Experience」を意図的に注入する作業です。AIには原理的に持てない要素なので、ここを人間が補うことで一気に独自性が出ます。
チェック3:論理の飛躍と矛盾を検証する
AIは流暢な文章を書きますが、内容の論理的整合性は保証されません。次の観点で検証します。
- 章をまたいで主張が一貫しているか確認する
- 結論と根拠の対応関係をチェックする(根拠が結論を支えているか)
- 「そのため」「しかし」が論理的に正しい接続になっているか確認する(機械的に挿入されていないか)
- 事実誤り(ハルシネーション)がないか、一次ソースで検証する
特にハルシネーション対策は手を抜けません。AIは「もっともらしい嘘」を堂々と書いてくるので、固有名詞・数値・歴史的事実は必ず元ソースに当たって確認してください。
チェック4:出典と根拠を明示する
統計や数値を使う際は、出典を必ず添えます。
- 統計・数値には出典名・調査機関・調査年・URLを明記する
- 公式ソース(Google検索セントラル、文部科学省、官公庁など)へのリンクを優先する
- 「〜と言われています」「一般的に〜」のような曖昧表現を避ける
- 「複数のメディアで紹介されている」だけで事実扱いせず、原典を確認する
これは、E-E-A-Tの「Trustworthiness」を担保する作業です。出典が一つもない記事は、AIで書いたかどうか以前に、読者からの信頼を得にくくなります。
チェック5:独自の視点と主張を一文加える
最後の仕上げが、独自の視点を加えることです。
- 一般論で終わらせず、書き手としての判断を1文加える
- 上位記事と異なる切り口を意識的に持つ
- 「私はこう考える」「実務ではこの方法を採用している」と明記する
- 「他の記事ではAと書いてあるが、自分はBの方が現実的だと考えている」のような対比も有効
E-E-A-Tの「Expertise」と「Authoritativeness」を強化する作業です。1文でかまわないので、必ず自分の判断を入れてください。これがあるかないかで、記事の存在意義そのものが変わってきます。
補足:ChatGPT等にセルフレビュー反復を実行させる
最後に、AIへの指示でアウトプットの質を上げる小技を紹介します。プロンプトの末尾に次の一文を加えるだけで、出力の質が変わります。
「生成後、レビューと改善を3回繰り返してください。」
シンプルな指示ですが、これだけでAIが「生成→自己レビュー→改善」のループを実行してくれます。この手法は、Aman Madaan氏ら16名の著者による論文「Self-Refine: Iterative Refinement with Self-Feedback」で有効性が科学的に実証されているものです。
ただし、3回繰り返したからといって完璧になるわけではありません。あくまで初稿の品質を底上げする手法であり、最後の品質チェックは前述の5項目を人間が手で行う必要があります。
AI文章のバレ方に関するよくある質問
ここでは、検索ユーザーから多く寄せられる質問にまとめて回答します。
- ChatGPTで書いた記事はGoogleペナルティを受けますか?
-
AI使用そのものはペナルティ対象ではありません。問題視されるのは「ランキング操作目的の大量生成」です。E-E-A-Tを満たした記事であれば、AI支援でも評価されます。
- AI検出ツールに通れば安心ですか?
-
残念ながら違います。検出ツールには偽陰性(AI文章を見逃す)も偽陽性(人間文章をAIと判定する)も多発します。Bloombergの検証では、ヒューマナイザーで処理することで98.1%判定が5.3%まで下がった事例も報告されています。
- AIで書いたことをクライアントに開示すべきですか?
-
クライアントの契約条件によります。AI使用禁止条項がある場合は守るのが大前提です。条項がない場合も、事前に「下書きにAIを使用するが、編集と事実確認は人手で行う」と合意しておくとトラブルを避けられます。
- 日本語のAI検出ツールでも検出されますか?
-
多くのツールは英語ベースで設計されており、日本語の検出精度は英語よりも低い傾向にあります。NABLAS社の発表によれば、20本のサンプルを用いた比較で、GPTZeroの日本語精度は71%、同社の日本語特化モデルは88%でした。日本語環境での過信は禁物です。
- AI記事でSEO上位を取ることは可能ですか?
-
可能です。Googleが評価するのは品質であって作成手段ではありません。AIで下書きを作り、人手で体験・固有情報・独自視点を注入したハイブリッド型の記事は、上位表示の事例が多数報告されています。重要なのは E-E-A-T を満たすことです。
まとめ:「バレるかどうか」より「読まれる価値を作れるか」
最後に、本記事の要点を3つに絞って振り返ります。
- 「AI 文章 バレる」は、検出ツール・編集者・Google・クライアントの4主体ごとに意味が変わる:自分のケースがどの主体に当たるかで対策が決まります
- AI検出ツールは万能ではない:公称精度と実測値には大きなギャップがあり、誤判定の被害事例も報告されています。Google公式もAI使用そのものをペナルティ対象にしていません
- 「バレない対策」より「品質チェック5項目」の方が長期的に得:定型表現を削り、固有情報を加え、論理を検証し、出典を明示し、独自視点を加える、という順番です
ここまで読んでくださった方は、もう「バレる/バレない」の不安に振り回される段階を抜けているはずです。検出ツールに怯えるのでも、人間化テクニックを延々と追いかけるのでもなく、「公開前のひと工程として品質チェックを組み込む」というシンプルな運用にたどり着けます。
次のアクションとして、まずは直近に書いた1記事を本記事の「品質チェック5項目」で見直してみてください。修正が入る箇所が思った以上に見つかるはずで、その作業の積み重ねが、検出ツールにも編集者にもGoogleにもクライアントにも通用する「あなたの記事の信頼性」になっていきます。